11.3 Acquisition Functions¶
A Gaussian process gives, at every input \(\mathbf{x}\), two numbers — a posterior mean \(\mu(\mathbf{x})\) and a posterior standard deviation \(\sigma(\mathbf{x})\). Bayesian optimisation reduces these two numbers to a single scalar, the acquisition function \(\alpha(\mathbf{x})\), and selects the next query as $$ \mathbf{x}\text{next} = \arg\max). $$ The acquisition function encodes the exploration-exploitation trade-off discussed in §11.1; its specific form embodies a specific stance on how to weight uncertain candidates relative to confident ones. This section derives the three workhorse acquisitions — expected improvement, upper confidence bound, Thompson sampling — discusses the knowledge gradient, sketches multi-objective extensions, and implements EI and UCB on the 1D example from §11.2.} \in \mathcal{X}} \alpha(\mathbf{x
We adopt the convention that the BO objective is maximisation (a band gap to maximise, an efficiency to maximise). Minimisation is recovered by negating the target.
Key Idea (Box 11.3.A)
An acquisition function \(\alpha(\mathbf{x})\) is a scalarisation of the surrogate posterior \((\mu(\mathbf{x}), \sigma(\mathbf{x}))\) that encodes the experimenter's preferences about the exploration-exploitation trade-off. The three workhorse choices — expected improvement, upper confidence bound, Thompson sampling — differ only in how they combine \(\mu\) and \(\sigma\) into a single number; the underlying surrogate is the same.
11.3.1 Expected Improvement¶
Let \(f^+ = \max_i y_i\) denote the best observed value so far, where the \(y_i\) are the noisy training labels (some authors use the latent function value at the best observed input; the difference is small in practice). Define the improvement of a candidate \(\mathbf{x}\) as $$ I(\mathbf{x}) = \max(f(\mathbf{x}) - f^+, 0). $$ This is non-negative: a candidate that exceeds the current best by \(\Delta\) achieves improvement \(\Delta\); a candidate that underperforms achieves zero improvement.
Under the GP posterior, \(f(\mathbf{x}) \sim \mathcal{N}(\mu(\mathbf{x}), \sigma^2(\mathbf{x}))\), and the improvement is a random variable. The expected improvement is the expectation of \(I(\mathbf{x})\) over this posterior: $$ \mathrm{EI}(\mathbf{x}) = \mathbb{E}!\left[\max(f(\mathbf{x}) - f^+, 0)\right]. $$ This is the central acquisition function of Bayesian optimisation. We derive its closed form.
Theorem 11.3.1 (Mockus 1975; Jones, Schonlau & Welch 1998)
Let \(f(\mathbf{x}) \sim \mathcal{N}(\mu(\mathbf{x}), \sigma^2(\mathbf{x}))\) with \(\sigma(\mathbf{x}) > 0\), and let \(f^+ \in \mathbb{R}\) be a fixed threshold. Define \(z = (\mu(\mathbf{x}) - f^+)/\sigma(\mathbf{x})\). Then the expected improvement is $$ \mathrm{EI}(\mathbf{x}) = \mathbb{E}!\left[\max(f(\mathbf{x}) - f^+, 0)\right] = (\mu(\mathbf{x}) - f^+)\Phi(z) + \sigma(\mathbf{x})\phi(z), $$ where \(\phi\) is the standard normal PDF and \(\Phi\) the standard normal CDF. Equivalently \(\mathrm{EI}(\mathbf{x}) = \sigma(\mathbf{x})[z \Phi(z) + \phi(z)]\).
Proof. See derivation below.
Let \(Z = (f(\mathbf{x}) - \mu(\mathbf{x})) / \sigma(\mathbf{x})\) be the standardised posterior variable; it is standard normal. Then \(f(\mathbf{x}) - f^+ = \sigma(\mathbf{x}) Z + (\mu(\mathbf{x}) - f^+)\). Define $$ z = \frac{\mu(\mathbf{x}) - f^+}{\sigma(\mathbf{x})}. $$ Then \(f(\mathbf{x}) - f^+ = \sigma(\mathbf{x})(Z + z)\), which is non-negative iff \(Z \geq -z\). Therefore $$ \mathrm{EI}(\mathbf{x}) = \int_{-z}^{\infty} \sigma(\mathbf{x})(z' + z) \phi(z') \, dz', $$ where \(\phi\) is the standard normal density. Splitting the integral, $$ \mathrm{EI}(\mathbf{x}) = \sigma(\mathbf{x}) \left[ z \int_{-z}^{\infty} \phi(z') \, dz' + \int_{-z}^{\infty} z' \phi(z') \, dz' \right]. $$ The first integral is \(1 - \Phi(-z) = \Phi(z)\), where \(\Phi\) is the standard normal CDF. The second uses \(\int z' \phi(z') dz' = -\phi(z')\): $$ \int_{-z}^{\infty} z' \phi(z') \, dz' = -\phi(z')\Big|_{-z}^{\infty} = \phi(-z) = \phi(z). $$ Assembling, $$ \boxed{ \mathrm{EI}(\mathbf{x}) = \sigma(\mathbf{x}) \left[ z \Phi(z) + \phi(z) \right], \qquad z = \frac{\mu(\mathbf{x}) - f^+}{\sigma(\mathbf{x})}. } \tag{11.4} $$ This is the form derived by Mockus (1975) and rediscovered by Jones, Schonlau and Welch (1998) — the latter is the paper most cited in the modern BO literature.
Two limits illuminate the formula.
When \(\mu \gg f^+\) and \(\sigma\) is moderate, \(z \to \infty\), \(\Phi(z) \to 1\), \(\phi(z) \to 0\), and \(\mathrm{EI} \to \mu - f^+\). The acquisition reduces to the predicted improvement — pure exploitation.
When \(\sigma \to 0\) at a point with \(\mu \leq f^+\), \(\mathrm{EI} \to 0\). A candidate the model is sure is no better than the current best is not worth investigating.
When \(\sigma\) is large at a point where \(\mu \approx f^+\), \(z \approx 0\), \(\Phi(0) = 1/2\), \(\phi(0) = 1/\sqrt{2\pi}\), and \(\mathrm{EI} \approx \sigma / \sqrt{2\pi}\). The acquisition grows linearly in \(\sigma\): uncertain candidates near the current best are attractive even if their mean is not exceptional.
This automatic trade-off is what makes EI so widely used. There is no explicit exploration parameter; the function naturally balances the two.
Remark 11.3.2 — alternative derivation via direct integration
Without the substitution, evaluate $$ \mathrm{EI}(\mathbf{x}) = \int_{f+}(f \mid \mu, \sigma^2) \, df. $$ Split the integrand: $$ \mathrm{EI} = \int_{f} (f - f^+) \, \mathcal{N+}\infty f \, \mathcal{N}(f | \mu, \sigma^2) df - f^+ \int_{f+}\infty \mathcal{N}(f | \mu, \sigma^2) df. $$ The second integral is \(\mathbb{P}(f \geq f^+) = \Phi(z)\) with \(z = (\mu - f^+)/\sigma\). For the first, use the identity (integration by parts on the Gaussian density) \(\int_{a}^\infty f \, \mathcal{N}(f | \mu, \sigma^2) df = \mu \Phi((\mu-a)/\sigma) + \sigma \phi((\mu-a)/\sigma)\). Substituting \(a = f^+\), \(\int_{f^+}^\infty f \, \mathcal{N}(\cdot) df = \mu \Phi(z) + \sigma \phi(z)\). Combining: \(\mathrm{EI} = \mu \Phi(z) + \sigma \phi(z) - f^+ \Phi(z) = (\mu - f^+)\Phi(z) + \sigma \phi(z)\), which agrees with Theorem 11.3.1. \(\square\)
EI has a known weakness: it can over-exploit when the posterior is badly miscalibrated. A small but stubborn refinement is exploration- augmented EI, which adds a small \(\xi > 0\) to the threshold: \(z = (\mu - f^+ - \xi) / \sigma\). With \(\xi\) in the range \(0.01\) to \(0.1\) (in the units of \(y\)), EI requires candidates to beat the current best by a comfortable margin before being scored — discouraging the algorithm from clustering around the current optimum. This trick is standard in production BO codes.
Proof of Theorem 11.3.1 (full)
We provide a clean, self-contained proof to complement the substitution-style argument above.
Let \(f \sim \mathcal{N}(\mu, \sigma^2)\). The improvement \(I = \max(f - f^+, 0)\) is non-negative and takes the value \(f - f^+\) when \(f \geq f^+\), zero otherwise. Therefore $$ \mathrm{EI} = \mathbb{E}[I] = \int_{-\infty}^{\infty} \max(f - f^+, 0) p(f) df = \int_{f+}\right) df. $$ Change variables to } (f - f^+) \cdot \frac{1}{\sigma}\phi!\left(\frac{f - \mu}{\sigma\(u = (f - \mu)/\sigma\), so \(f = \mu + \sigma u\) and \(df = \sigma du\). The lower limit becomes \(u_0 = (f^+ - \mu)/\sigma = -z\) (using our convention \(z = (\mu - f^+)/\sigma\)). The integrand transforms: \(f - f^+ = \mu + \sigma u - f^+ = \sigma(u + z)\). The density transforms: \(\frac{1}{\sigma}\phi(u) \cdot \sigma du = \phi(u) du\). Therefore $$ \mathrm{EI} = \int_{-z}^{\infty} \sigma(u + z) \phi(u) du = \sigma\left[\int_{-z}^\infty u \phi(u) du + z \int_{-z}^\infty \phi(u) du\right]. $$ For the first integral, use \(\frac{d}{du}\phi(u) = -u\phi(u)\), so \(\int u\phi(u)du = -\phi(u)\). Therefore \(\int_{-z}^\infty u\phi(u)du = -\phi(u)|_{-z}^\infty = 0 - (-\phi(-z)) = \phi(-z) = \phi(z)\) (using symmetry of \(\phi\)). For the second integral, \(\int_{-z}^\infty \phi(u)du = 1 - \Phi(-z) = \Phi(z)\). Substituting: $$ \mathrm{EI} = \sigma\left[\phi(z) + z \Phi(z)\right] = \sigma z \Phi(z) + \sigma \phi(z) = (\mu - f^+)\Phi(z) + \sigma \phi(z), $$ where the last step uses \(\sigma z = \mu - f^+\) from the definition of \(z\). \(\square\)
The proof is short but builds in several non-trivial facts: the substitution, the symmetry of the standard normal, and the fundamental theorem of calculus for the Gaussian density. Internalising these is more useful in the long run than memorising the formula.
Remark 11.3.1a — degenerate case \(\sigma = 0\)
When \(\sigma = 0\) the candidate has no uncertainty, and EI must be defined by limit. There are two cases: \(\mu > f^+\) gives \(\mathrm{EI} = \mu - f^+ > 0\) (a guaranteed improvement); \(\mu \leq f^+\) gives \(\mathrm{EI} = 0\) (no improvement, no uncertainty). The closed form \((\mu - f^+)\Phi(z) + \sigma\phi(z)\) becomes \((\mu - f^+) \cdot \mathbb{1}[\mu > f^+]\) in the limit, which agrees. Production code adds a small epsilon to \(\sigma\) before computing \(z\) to avoid division by zero.
Pause and recall
Before reading on, try to answer these from memory:
- What is the role of an acquisition function in Bayesian optimisation — how does it turn the GP posterior into a decision?
- Define the improvement \(I(\mathbf{x})\) and explain why Expected Improvement is its expectation under the GP posterior.
- In the closed form \(\mathrm{EI} = (\mu - f^+)\Phi(z) + \sigma\phi(z)\), which term rewards exploitation and which rewards exploration?
If any of these is shaky, re-read the preceding section before continuing.
11.3.2 Upper Confidence Bound¶
The upper confidence bound (UCB) is simpler: $$ \boxed{ \mathrm{UCB}(\mathbf{x}) = \mu(\mathbf{x}) + \kappa \sigma(\mathbf{x}). } \tag{11.5} $$ It scores each candidate as the upper edge of a \(\kappa\)-standard- deviation confidence interval around its mean. Large \(\kappa\) favours high-uncertainty candidates; small \(\kappa\) favours high-mean candidates.
The trade-off here is fully explicit and externally controlled. Two common choices for \(\kappa\).
Fixed \(\kappa\). Set \(\kappa = 2\) (corresponding to a 95% upper bound under Gaussian assumptions). Simple, predictable, used widely in practice.
Time-decaying \(\kappa\). Set \(\kappa_t = \sqrt{2 \log(t^2 \pi^2 / (6\delta))}\) where \(t\) is the iteration index and \(\delta\) is a small constant. This is the schedule from Srinivas et al. (2010), who proved that GP-UCB with this schedule has sublinear regret — the average per- iteration suboptimality decays to zero as \(t \to \infty\). The schedule explores aggressively early and exploits late.
Theorem 11.3.3 (Srinivas, Krause, Kakade & Seeger 2010)
Let \(f\) be sampled from a GP with kernel \(k\), and let \(\mathbf{x}_t = \arg\max \mathrm{UCB}_t(\mathbf{x})\) with \(\kappa_t^2 = 2 \log(|\mathcal{X}| t^2 \pi^2 / (6\delta))\) for a finite candidate set \(\mathcal{X}\). Then with probability at least \(1 - \delta\), the cumulative regret satisfies $$ R_T = O!\left(\sqrt{T \gamma_T \log T}\right), $$ where \(\gamma_T\) is the maximum information gain after \(T\) rounds (a kernel-dependent quantity that grows polylogarithmically for RBF kernels in fixed dimension).
The proof proceeds by bounding the instantaneous regret \(r_t = f^* - f(\mathbf{x}_t)\) by \(2\kappa_t \sigma_t(\mathbf{x}_t)\) and using a union bound to ensure UCB upper-bounds \(f\) everywhere with high probability. Summing \(r_t\) over \(t\) and applying a Cauchy-Schwarz inequality on \(\sum_t \sigma_t(\mathbf{x}_t)^2\) — which is bounded by \(\gamma_T\) — gives the stated rate.
UCB is in some sense the most theoretically grounded acquisition, with sharper regret bounds than EI. In practice the two are competitive; UCB is preferred when one wants explicit control over the exploration-exploitation balance, EI when one wants a sensible default.
11.3.3 Thompson sampling¶
Thompson sampling has the most distinctive flavour of the three. At each iteration, sample a function \(\tilde f\) from the GP posterior and select the next query as the maximum of the sample: $$ \mathbf{x}\text{next} = \arg\max), \qquad \tilde f \sim p(f \mid \mathcal{D}). $$ Where does the trade-off come from? In regions where the GP is confident, samples cluster around the posterior mean; the sampled maximum reliably lies near the posterior maximum (exploit). In regions where the GP is uncertain, different samples assign wildly different function values; the sampled maximum sometimes lies in those uncertain regions (explore). The randomness of the sample mixes the two.}} \tilde f(\mathbf{x
A practical wrinkle: drawing a function from a GP is expensive — the sample is jointly Gaussian over all candidate inputs, so one must sample from a multivariate Gaussian with covariance of size \(N \times N\) where \(N\) is the candidate count. For \(N \lesssim 10^4\) this is tractable. For larger \(N\), random Fourier features allow approximate sampling at much lower cost.
Thompson sampling is particularly elegant in batch settings: drawing \(B\) independent function samples and selecting their respective maxima naturally diversifies the batch, without requiring an explicit batch acquisition function. BoTorch supports this directly.
Example 11.3.4 — Thompson sampling on a two-point posterior
Suppose we have a 1D GP with posterior \(\mathcal{N}(0, 1)\) at \(x = 0\) and \(\mathcal{N}(1, 0.01)\) at \(x = 1\), with very small cross-covariance. A Thompson sample at the two points is a vector drawn from a 2D Gaussian. Typical draw: \((-0.3, 1.05)\) — selects \(x = 1\). Another typical draw: \((2.1, 1.02)\) — selects \(x = 0\) because the random sample at \(x = 0\) exceeded the (almost-fixed) sample at \(x = 1\). The first case is exploitation; the second is exploration. The probability of exploration is exactly the probability that \(f(x=0) > f(x=1)\) under the joint posterior, which is \(\Phi(-1/\sqrt{1.01}) \approx 0.16\). The randomness of the sample implements the trade-off without an explicit exploration parameter.
11.3.4 The Knowledge Gradient¶
The acquisitions so far ask "what is the immediate improvement from querying \(\mathbf{x}\)?" — a one-step-lookahead. The knowledge gradient (KG) asks a more refined question: "after querying \(\mathbf{x}\) and updating the GP, how much better is my future predicted best value than my current predicted best?" Formally, $$ \mathrm{KG}(\mathbf{x}) = \mathbb{E}!\left[ \max_{\mathbf{x}'} \mu_{t+1}(\mathbf{x}') \;\bigg|\; \text{queried } \mathbf{x} \right] - \max_{\mathbf{x}'} \mu_t(\mathbf{x}'). $$ The expectation is over the posterior distribution of the next observation \(y_{t+1}\). The integral cannot in general be done in closed form, but can be approximated by Monte Carlo sampling.
KG is the natural acquisition when the goal is the final recommendation after the campaign, not the best in-progress value. It handles noisy observations and finite-budget terminal-reward problems more naturally than EI, at the cost of harder optimisation.
In practice KG is used when its higher quality justifies the implementation overhead — primarily in industrial chemistry and process optimisation. For most academic materials BO, EI is the default, with UCB as the explicit-control alternative.
11.3.4a Comparison of acquisition functions¶
A summary table consolidates the trade-offs.
| Acquisition | Formula | Exploration knob | Closed form | Theoretical regret bound | Best for |
|---|---|---|---|---|---|
| Probability of Improvement (PI) | \(\Phi(z)\) | \(\xi\) in threshold | yes | weak | sharp exploitation |
| Expected Improvement (EI) | \((\mu - f^+)\Phi(z) + \sigma\phi(z)\) | implicit via \(\sigma\) | yes | \(O(\sqrt{T \log T})\) | default for noiseless |
| Upper Confidence Bound (UCB) | \(\mu + \kappa\sigma\) | \(\kappa\) | yes | \(O(\sqrt{T \gamma_T \log T})\) | explicit control, bandits |
| Thompson Sampling (TS) | argmax of sample | implicit, random | sample | \(O(\sqrt{T \log T})\) | batch BO |
| Knowledge Gradient (KG) | \(\mathbb{E}[\max_{\mathbf{x}'}\mu_{t+1}] - \max_{\mathbf{x}'}\mu_t\) | implicit | Monte Carlo | strongest for terminal | noisy / terminal-reward |
| Predictive Entropy Search (PES) | $H[\mathbf{x}^* | \mathcal{D}] - \mathbb{E}_y H[\mathbf{x}^* | \mathcal{D}, \mathbf{x}, y]$ | implicit | Monte Carlo |
Notes on the table:
- \(z = (\mu - f^+) / \sigma\) throughout.
- PI is mentioned here for completeness; it is rarely used in modern BO because it over-exploits without the \(\xi\) trick and is dominated by EI in practice.
- Regret bounds presume mild kernel assumptions and a sufficiently large candidate set. The Big-\(O\) notation hides constants that vary by acquisition.
- "Closed form" means the acquisition can be evaluated without Monte Carlo; "Monte Carlo" means typical implementation uses 100–1000 samples to approximate the expectation.
The first three rows are the canonical "vanilla" acquisitions; the last three are advanced choices used when their specific properties are needed.
11.3.5 When each is the right choice¶
A practical guide:
- Use EI as the default when:
- your objective is real-valued and the goal is to maximise it,
- you have a single objective (not Pareto),
- your GP is reasonably well-calibrated,
-
you have moderate observation noise (variance noise/signal of order 1).
-
Use UCB when:
- you need explicit, tunable control over exploration vs exploitation,
- you are tracking theoretical regret bounds,
-
you want a smoother acquisition surface (UCB is easier to optimise than EI for some kernels).
-
Use Thompson sampling when:
- you want batch BO without writing a batch acquisition,
- you want a fully Bayesian feel to the algorithm,
-
your candidate set is small enough to draw posterior samples.
-
Use Knowledge Gradient when:
- you have noisy observations and care only about the terminal recommendation,
- the implementation effort is justified by the problem stakes.
For multi-objective problems, none of the above apply directly; see the next subsection.
Example 11.3.5 — EI numerical evaluation
Suppose at a candidate \(\mathbf{x}\) the GP gives \(\mu = 0.8\), \(\sigma = 0.3\), and the current best is \(f^+ = 1.0\). Compute EI.
Step 1. \(z = (0.8 - 1.0)/0.3 = -2/3 \approx -0.667\).
Step 2. \(\Phi(-0.667) \approx 0.253\) (left-tail CDF).
Step 3. \(\phi(-0.667) = \phi(0.667) \approx 0.319\).
Step 4. \(\mathrm{EI} = (0.8 - 1.0) \cdot 0.253 + 0.3 \cdot 0.319 \approx -0.0506 + 0.0957 \approx 0.045\).
The candidate has a positive EI of about 0.045 despite having posterior mean below the current best, because the uncertainty band extends above \(f^+\). Compare with a candidate that has \(\mu = 0.95, \sigma = 0.05\): \(z = -1\), \(\Phi(-1) \approx 0.159\), \(\phi(-1) \approx 0.242\), \(\mathrm{EI} = -0.05 \cdot 0.159 + 0.05 \cdot 0.242 \approx 0.004\). The second candidate has higher mean but lower EI — its uncertainty is too small to plausibly exceed \(f^+\). EI correctly prefers the more uncertain candidate. This is the exploration contribution working as designed.
Remark 11.3.6 — Probability of Improvement vs Expected Improvement
A related acquisition is the probability of improvement (PI): \(\mathrm{PI}(\mathbf{x}) = \mathbb{P}(f(\mathbf{x}) > f^+) = \Phi(z)\). It is the probability that \(f\) exceeds the best, with no regard for by how much it exceeds. PI is greedy: it favours candidates with small but reliable improvements over candidates with large but uncertain ones. EI corrects this by weighting by the size of the improvement, hence the extra \(\sigma \phi(z)\) term.
In practice PI is almost always dominated by EI, and EI is the correct default. PI survives as a simple baseline and as a special case of EI with \(\xi\) very large.
11.3.6 Multi-objective BO and Pareto fronts¶
Most materials problems have more than one objective. A high-performance solar cell needs both high efficiency and low cost; a structural alloy needs strength and ductility. The two objectives are usually in tension, and there is no single best material — instead a Pareto front of materials that cannot be improved on one objective without worsening another.
The standard acquisition for multi-objective BO is expected hypervolume improvement (EHVI). Given a set of observed objective vectors \(\{(y_1^{(i)}, y_2^{(i)}, \ldots, y_M^{(i)})\}\), define the dominated hypervolume as the volume of the region in objective space dominated by at least one observed point (bounded by a reference point). EHVI asks: if we query candidate \(\mathbf{x}\), how much do we expect to grow the dominated hypervolume?
For two objectives EHVI is computable in closed form via a partition
of the dominated region; for three or more objectives one resorts to
Monte Carlo. BoTorch implements this directly via
qExpectedHypervolumeImprovement, which is the right starting point
for any multi-objective materials problem.
Example 11.3.7 — Pareto front for strength vs ductility
A structural alloys problem with two objectives: yield strength (maximise) and elongation-to-failure (maximise). Three observed alloys have \((\sigma_y, \epsilon) = (300, 0.4), (500, 0.2), (700, 0.1)\) MPa and fractional strain respectively. None dominates the others: each excels on one axis. The Pareto front is the polyline connecting these three. The dominated hypervolume, with reference point \((\sigma_y^\text{ref}, \epsilon^\text{ref}) = (0, 0)\), is the union of three rectangles, with total area approximately \(300 \cdot 0.4 + 200 \cdot 0.2 + 200 \cdot 0.1 = 180\) MPa-strain. Querying a new candidate that achieves \((600, 0.3)\) would extend the front and grow the hypervolume by approximately \(100 \cdot 0.1 = 10\) — significant improvement. The EHVI ranks candidates by the expected such growth.
The conceptual content is the same as single-objective EI — quantify the expected improvement under the surrogate's posterior, query the candidate that maximises it — generalised from a scalar to a Pareto- front objective. We will use EHVI in the perovskite case study of §11.4.
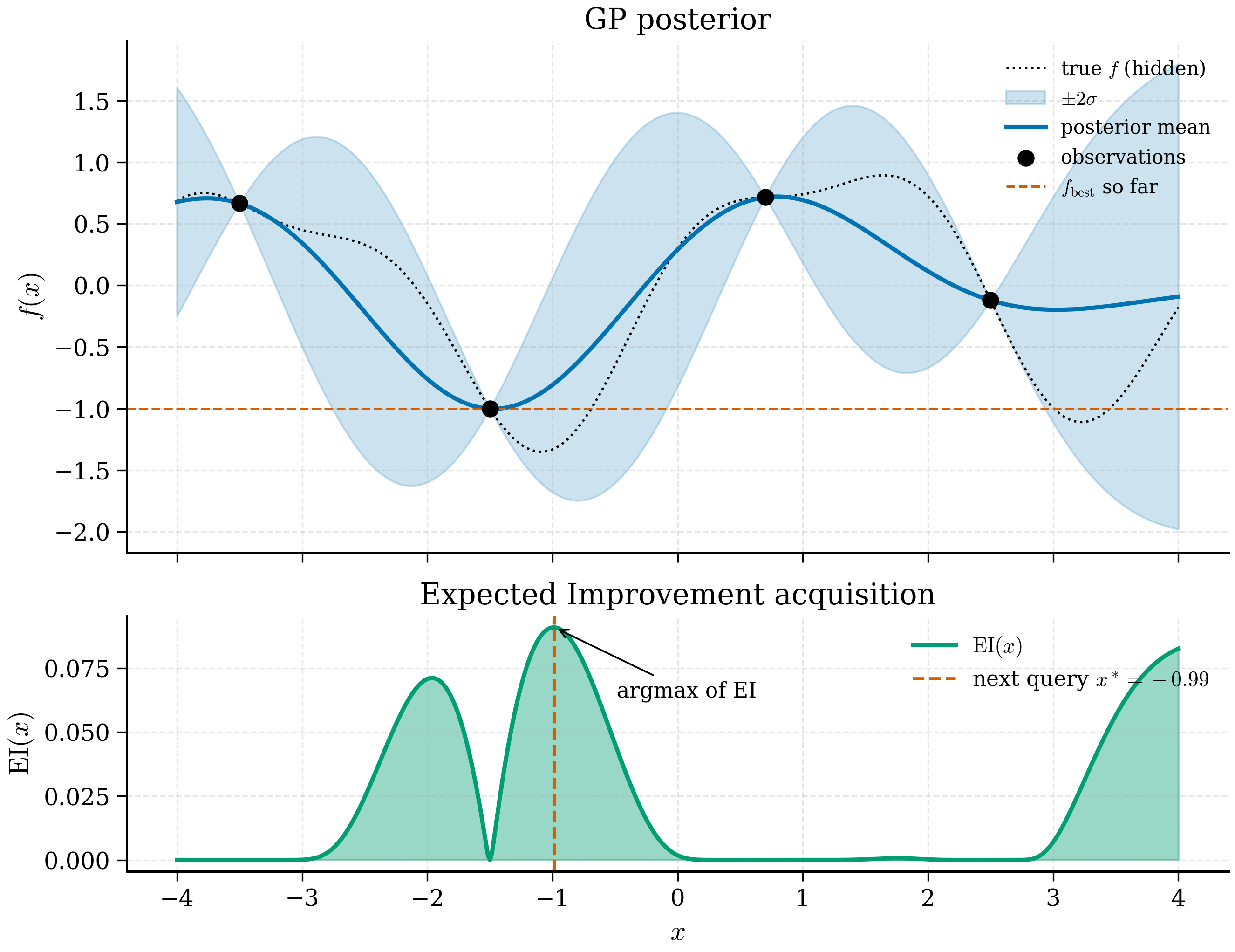
11.3.7 Implementation: EI and UCB on the 1D example¶
We extend the GP from §11.2.6 with acquisition functions and run a short BO loop on the sine objective.
"""Acquisition functions and a short BO loop."""
from __future__ import annotations
import numpy as np
from numpy.typing import NDArray
from scipy.stats import norm
# Assume GP from 02-gp.md is imported.
def expected_improvement(
gp: GP,
X: NDArray[np.float64],
f_best: float,
xi: float = 0.01,
) -> NDArray[np.float64]:
"""Expected improvement for a maximisation objective."""
mu, var = gp.predict(X)
sigma = np.sqrt(np.maximum(var, 1e-12))
z = (mu - f_best - xi) / sigma
ei = sigma * (z * norm.cdf(z) + norm.pdf(z))
ei[sigma < 1e-9] = 0.0 # zero-uncertainty points get no EI
return ei
def upper_confidence_bound(
gp: GP,
X: NDArray[np.float64],
kappa: float = 2.0,
) -> NDArray[np.float64]:
"""UCB acquisition."""
mu, var = gp.predict(X)
return mu + kappa * np.sqrt(np.maximum(var, 1e-12))
Demonstration: maximise \(f(x) = \sin(x)\) on \(x \in [0, 7]\) starting from three initial observations.
import matplotlib.pyplot as plt
rng = np.random.default_rng(0)
true_f = lambda x: np.sin(x)
noise_level = 0.05
# Initial training data
X_init = np.array([[1.5], [3.0], [5.0]])
y_init = true_f(X_init.flatten()) + rng.normal(0, noise_level, size=3)
X_train = X_init.copy()
y_train = y_init.copy()
# Candidate set for acquisition optimisation (dense grid for 1D)
X_cand = np.linspace(0, 7, 500).reshape(-1, 1)
for iteration in range(10):
gp = GP()
gp.optimise_hyperparameters(X_train, y_train)
f_best = float(np.max(y_train))
ei = expected_improvement(gp, X_cand, f_best, xi=0.01)
x_next = X_cand[np.argmax(ei)].reshape(1, -1)
y_next = true_f(float(x_next)) + rng.normal(0, noise_level)
X_train = np.vstack([X_train, x_next])
y_train = np.append(y_train, y_next)
print(
f"iter {iteration:2d}: queried x = {float(x_next):.3f}, "
f"y = {y_next:+.3f}, best so far = {np.max(y_train):+.3f}"
)
# Final plot
gp = GP()
gp.optimise_hyperparameters(X_train, y_train)
mu, var = gp.predict(X_cand)
std = np.sqrt(var)
ei = expected_improvement(gp, X_cand, float(np.max(y_train)), xi=0.01)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 6), sharex=True)
ax1.plot(X_cand.flatten(), true_f(X_cand.flatten()), "k--", label="truth")
ax1.plot(X_cand.flatten(), mu, "b-", label="GP mean")
ax1.fill_between(X_cand.flatten(), mu - 2 * std, mu + 2 * std, alpha=0.2)
ax1.scatter(X_train.flatten(), y_train, c="red", s=30, label="queries")
ax1.legend()
ax1.set_ylabel("f(x)")
ax2.plot(X_cand.flatten(), ei, "g-")
ax2.set_xlabel("x")
ax2.set_ylabel("EI(x)")
plt.tight_layout()
plt.show()
Typical run output:
iter 0: queried x = 1.566, y = +1.001, best so far = +1.001
iter 1: queried x = 6.293, y = -0.018, best so far = +1.001
iter 2: queried x = 1.535, y = +1.013, best so far = +1.013
...
iter 9: queried x = 1.572, y = +0.996, best so far = +1.013
By iteration 2 the algorithm has localised the global maximum at \(x \approx \pi/2\) (true maximum \(\sin(\pi/2) = 1\)), then alternates between confirming it and probing other regions to confirm no better maximum exists. The acquisition surface at convergence is essentially flat — the GP is confident everywhere — and the BO loop has converged.
If we replace EI with UCB and set \(\kappa = 2\), the qualitative behaviour is similar but the algorithm spends more time probing high-variance regions early. Setting \(\kappa = 5\) explores even more aggressively, sometimes at the cost of slower convergence to the maximum but with stronger guarantees that no better maximum has been missed.
11.3.7a Iteration-by-iteration narrative: what the BO sees¶
Walk through the first three iterations of the BO loop above in narrative form.
Iteration 0. Three initial observations at \(x = 1.5, 3.0, 5.0\) yield \(y \approx 1.0, 0.14, -0.96\). The GP fits a posterior with mean that interpolates these three points and uncertainty bands wider in between and at the edges. EI as a function of \(x\) peaks near \(x = 1.5\), where the mean is already near 1 and the uncertainty band just barely admits values exceeding 1. The argmax of EI lies very close to \(x = 1.566 \approx \pi/2\), the true maximum.
Iteration 1. The new observation at \(\pi/2\) confirms the maximum. The GP posterior tightens around the new point. Now EI is suppressed near \(\pi/2\) (uncertainty has collapsed) and shifts attention to regions where the GP is unsure — typically \(x = 0\) (left edge) or \(x \approx 6.3\) (right side, beyond the data). The algorithm queries \(x \approx 6.3\), where the truth is \(\sin(6.3) \approx 0.0\). Mild explorative behaviour.
Iteration 2. Now the GP knows the function on \([1.5, 6.3]\) roughly well. EI is small everywhere except possibly at very fine refinements of the maximum. The next query is back near \(\pi/2\), refining the estimate of \(\sin(\pi/2)\).
This pattern — first localise the optimum, then probe the boundaries, then refine — is generic to EI-driven BO. UCB with large \(\kappa\) would interleave more boundary probes before settling near the optimum; Thompson sampling would have a stochastic visit pattern.
11.3.7b The non-myopia question¶
EI, UCB and Thompson sampling are all myopic: they choose the next query as if it were the last. Knowledge Gradient is partially non-myopic: it considers the effect of the query on the next-step posterior. Truly non-myopic acquisitions consider the effect of the query on the final posterior at the end of the budget. These are much harder to compute (the integration is over a tree of possible future query trajectories) and rarely used outside specialist literature.
The practical impact: with budgets of 20–100 queries, myopic acquisitions are typically within 10–20% of the optimal non-myopic acquisition. The gap matters in settings with very small budgets (\(T \leq 10\)) or very expensive evaluations, where the optimal allocation of the next query depends strongly on what we plan to do with the remaining ones. Roll-out BO (Lam et al. 2016) and BORE (Tiao et al. 2021) are advanced strategies that approximate non-myopic behaviour at moderate cost.
11.3.8 Where we are¶
We have a GP that produces calibrated posteriors and a family of acquisition functions that turn those posteriors into action. Combined, they constitute the full Bayesian optimisation algorithm:
- Initialise with a few queries (random or quasi-random).
- Fit GP, optimise hyperparameters.
- Optimise the acquisition function to pick the next query.
- Evaluate the objective at the chosen query, append to data.
- Return to step 2 until budget is exhausted.
This loop, with EI on a GP, is what BoTorch and GPyOpt and Trieste all implement under the hood. The remaining mathematical machinery is mostly engineering: batch acquisitions, multi-fidelity, constraints, high-dimensional adaptations.
Section 11.4 turns to applications: how to apply this machinery to real materials-discovery problems. The featurisation choices (what \(\mathbf{x}\) should look like for a candidate material), the choice of oracle (DFT, MLIP, experiment), and the practical workflow with BoTorch are the subjects of the next section.
Section summary¶
- An acquisition function \(\alpha(\mathbf{x})\) scalarises the posterior \((\mu, \sigma)\) into a single value to maximise; the argmax becomes the next query.
- Expected Improvement (Theorem 11.3.1): \(\mathrm{EI} = (\mu - f^+)\Phi(z) + \sigma\phi(z)\); closed form, automatic exploration-exploitation balance.
- Upper Confidence Bound: \(\mathrm{UCB} = \mu + \kappa \sigma\); explicit knob \(\kappa\); with \(\kappa_t = O(\sqrt{\log t})\), sublinear regret (Theorem 11.3.3).
- Thompson sampling: sample function from posterior, return its argmax; trade-off implicit in the sample randomness; ideal for batch BO.
- Knowledge Gradient: one-step-lookahead version of EI; harder to compute but better for noisy/terminal-reward problems.
- Multi-objective generalisation: Expected Hypervolume Improvement.
Cross-reference
Chapter 12 will use these same acquisition functions atop foundation-model surrogates; the mathematics carries over unchanged. The acquisition functions are the part of the BO machinery that no scaling story replaces.